
Kaggle比赛教你最快速度入门文本分类(经典方法篇)
本篇文章是自然语言处理系列的第一篇,介绍最基本的文本分类问题解决方案:Logistic Regression、TF-IDF。数据集使用的是Kaggle竞赛中的Toxic评论分类挑战赛。
文本分类的基本流程:读取数据清洗数据特征提取模型训练模型评估
Kaggle竞赛的数据一般有train、test和sample_submission,我们用pandas来读取需要的数据。
labels是我们需要将文本分为的六个类别。
机器学习工作中广为流传的一句话:“数据决定机器学习的上限,算法让我们不断逼近这个上限”。
一个干净的数据集是我们在运用机器学习算法取得成功的关键,因此,对文本进行合适的处理是非常关键的一步。
以下是我在清洗文本过程中主要完成的工作:把你的文章分成一个个单独的单词。将所有字符转换为小写。删除所有不相关的字符,例如任何非字母、数字字符。恢复所有简写形式的单词考虑将“@$&”等字符转换为“at,dollar,and”。最后,有很多单词是拼写错误的,这个部分还需要想办法来处理大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
我们看看清洗前和清洗后的数据,效果还算是不错大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
自然语言处理的一个难点问题就是如何表示文本,机器学习模型都是以数值为输入,所以我们需要找到一种很好的表达方式让我们的算法能够理解文本数据。
为了帮助我们的模型更多地关注有意义的单词,我们可以使用TF-IDF进行特征提取。
这里,我们使用了sklearn库中的TfidfVectorizer来提取TF-IDF特征。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
本篇文章是第一篇,所以我们使用一个非常简单的Logistic Regression模型来进行分类。
首先,将训练数据划分为训练集和验证集。
我们保留了训练集中的0.1为验证集,用来评估我们的模型性能。
对于分类问题,我们用准确率来评估算法。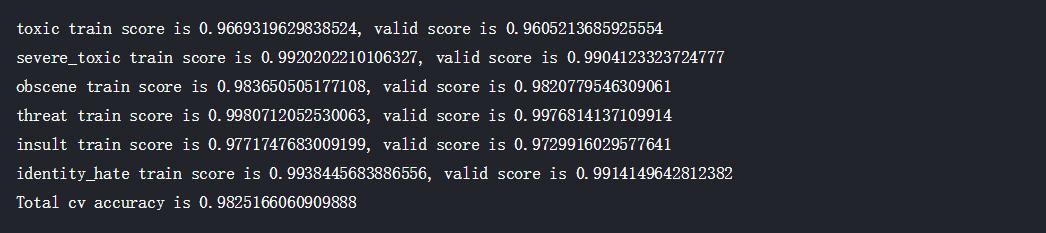
好了,我们用非常简单的Logistics Regression算法就在文本分类问题上获得了98.2%的准确率,表现已经非常不错。核心代码已经放出来了,有兴趣的同学可以在Kaggle上下载数据集,自己一步一步实现,印象会更深一些。
打个广告,欢迎关注我的微信公众号:Kaggle数据分析。专注分享Kaggle比赛的实战经验。
")
")







